
Best AI Models 2026: The Complete LLM Comparison Guide
Update — July 26, 2026: OpenAI has released the GPT-5.6 family with Sol, Terra, and Luna. The benchmark table below preserves its May 2026 comparison snapshot; for current OpenAI access, reasoning modes, API prices, and model-selection guidance, read our GPT-5.6 in ChatGPT guide.
Best AI Models 2026
Quick answer:
No single AI model is best at everything in 2026. Claude Opus 4.7 (Anthropic) leads on coding at 87.6% SWE-bench Verified. Gemini 3.1 Pro (Google DeepMind) leads on reasoning at 94.3% GPQA Diamond. GPT-5.5 (OpenAI) leads on agentic workflows at 82.7% Terminal-Bench. Pick based on your primary task, not headlines.
Best AI model by task: quick verdict
If you only need the short answer, use this decision table first. The detailed benchmark and pricing sections below explain the trade-offs.
| Use case | Best pick | Budget pick | Why it wins |
|---|---|---|---|
| Coding and code review | Claude Opus 4.7 | Gemini 3.1 Pro | Best hard-code benchmark results and strongest long-context debugging. |
| Reasoning and research | Gemini 3.1 Pro | Claude Opus 4.7 | Strongest published reasoning scores and good price-to-performance. |
| Agents and computer use | GPT-5.5 | Claude Opus 4.7 | Best fit for tool use, autonomous workflows, and ChatGPT ecosystem tasks. |
| High-volume API workloads | DeepSeek V4 Flash | Gemini Flash tier | Lowest token cost for teams processing large batches. |
| Business writing and strategy | Claude Opus 4.7 | Claude Sonnet 4.6 | Most reliable long-form writing and lower hallucination risk. |
Key takeaways
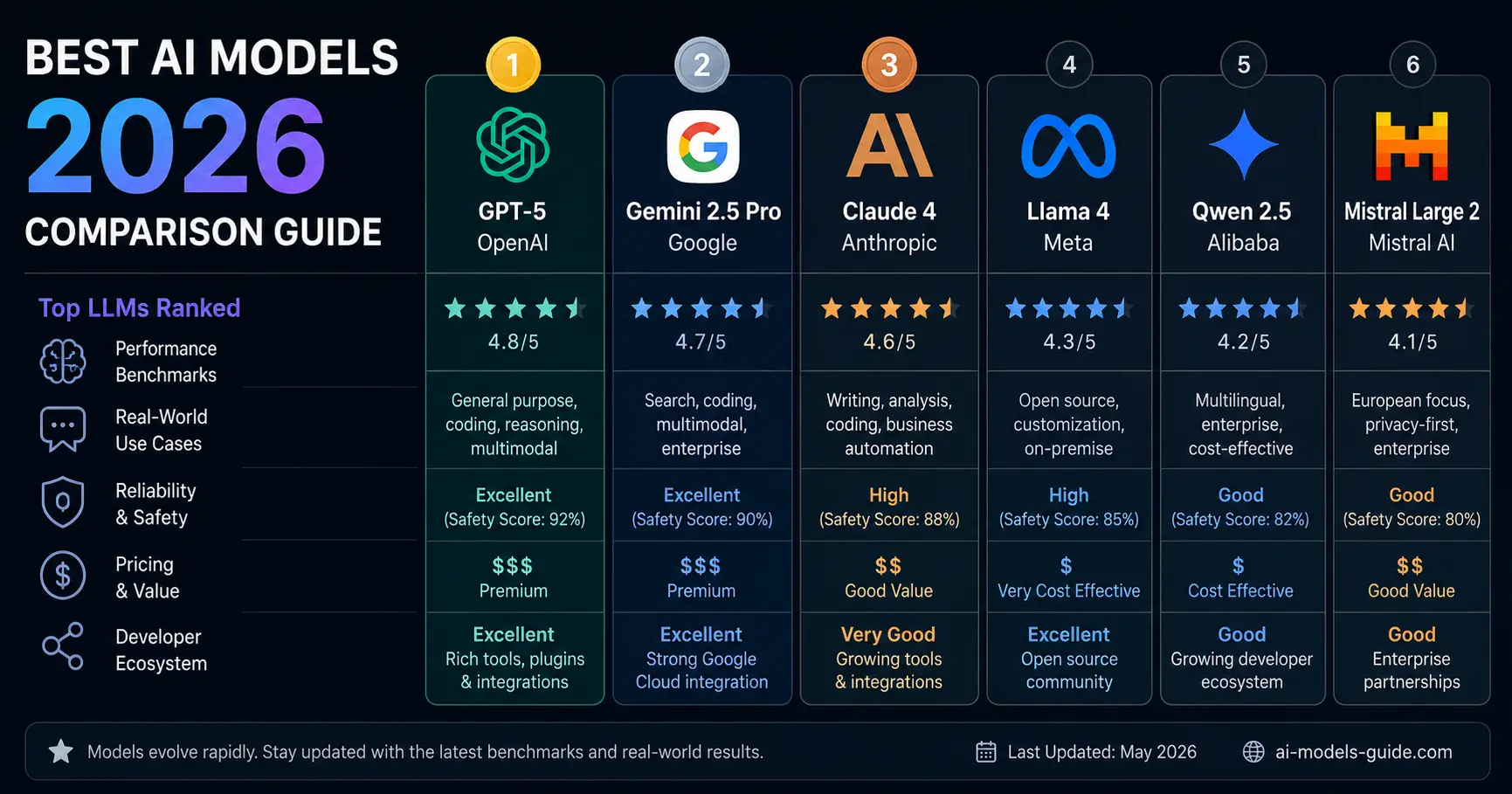
- The top five frontier models in May 2026 are Claude Opus 4.7, GPT-5.5, Gemini 3.1 Pro, Grok 4.3, and DeepSeek V4 Pro. All five score within three points of each other on the Artificial Analysis Intelligence Index.
- Gemini 3.1 Pro is the price-performance leader among closed frontier models at $2 per million input tokens. DeepSeek V4 Flash is the cheapest production-grade option at $0.14 per million input tokens.
- Consumer pricing has converged: Claude Pro, ChatGPT Plus, and Google AI Pro all cost $20 per month as of May 2026.
- Gartner forecasts worldwide AI spending at $2.52 trillion in 2026. The average enterprise now runs 4.2 AI models in production, up from 1.9 in 2023.
- Multi-model routing — directing different request types to different models — has become standard architecture. It achieves near-frontier performance at roughly 15% of the all-frontier cost.
- Claude Opus 4.7 leads on complex coding and long-form writing. Gemini 3.1 Pro leads on scientific reasoning and multimodal tasks. GPT-5.5 leads on autonomous agents and computer use.
LLM Stats tracked 255 major model releases in Q1 2026 alone. Roughly one meaningful new model dropped every single day. If you bookmarked a “best AI models” list more than six weeks ago, it is already outdated.
The race between OpenAI, Anthropic, Google DeepMind, xAI, and DeepSeek has compressed the performance gap between top models to within a few benchmark points. But the benchmarks that matter have also changed. The “best” model is no longer a simple ranking. It is a task-by-task decision that depends on what you actually need: coding quality, reasoning depth, multimodal capability, or raw cost efficiency.
This guide gives you the updated June 2026 picture: every major model, every benchmark that matters, verified pricing from official sources, and a clear decision framework so you stop paying for the wrong model.
The state of LLMs in 2026: what changed
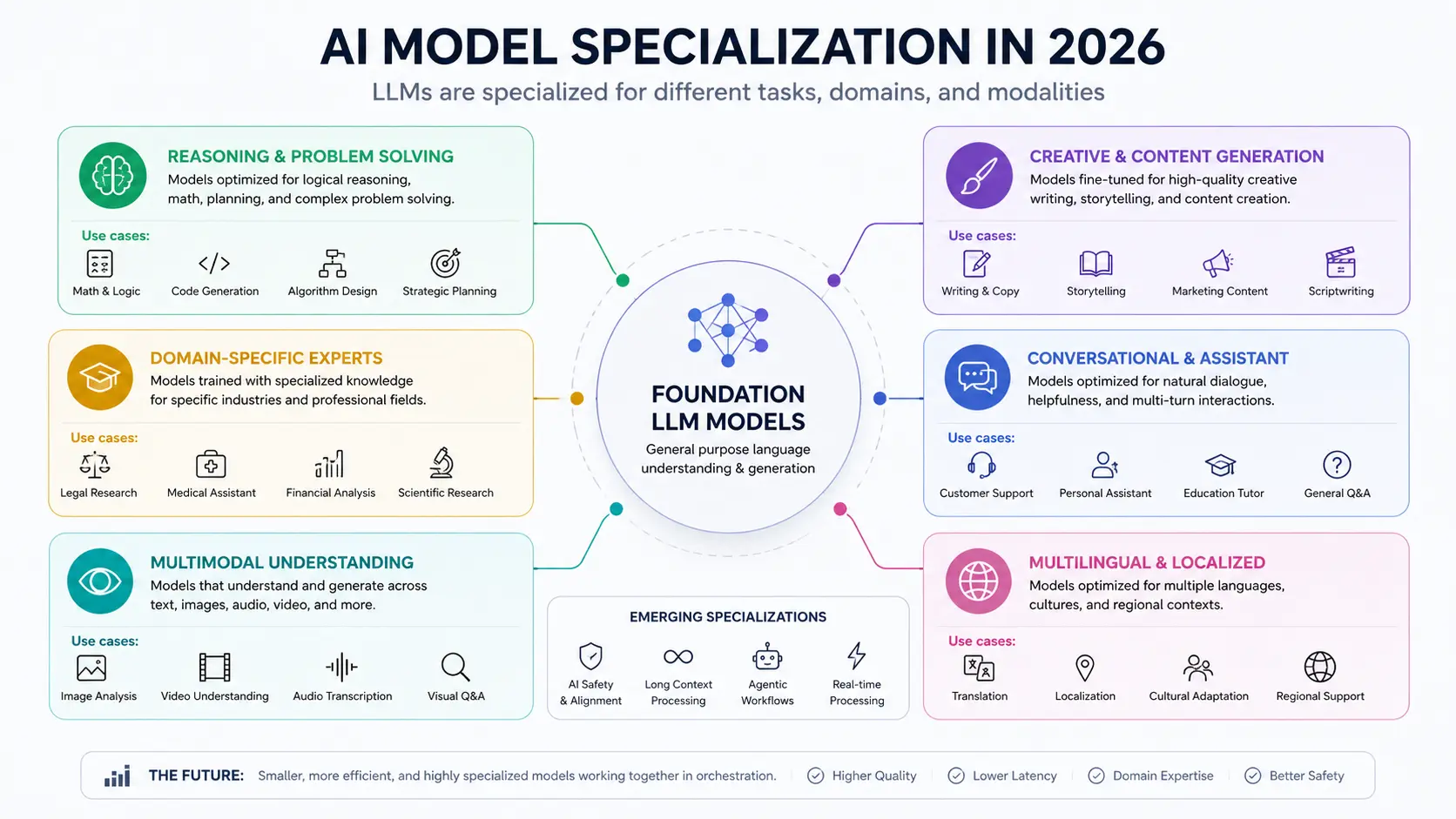
Three shifts define the AI model landscape in May 2026, and they matter before you look at any benchmark.
Specialization replaced the single-winner model
Through 2024, every major lab chased a single number: overall benchmark rank. In 2026, that race has splintered. Claude Opus 4.7 leads SWE-bench Pro. Gemini 3.1 Pro leads GPQA Diamond. GPT-5.5 leads Terminal-Bench. Grok 4.3 leads Humanity’s Last Exam. Each claim is legitimate. Each tells you something specific and useful about what that model is actually good at.
The practical implication is that “which AI is best” is now the wrong question. The right questions are: best for coding, best for writing, best for reasoning, best for video, best at a price point. This guide answers all of them.
Open-weight models reached frontier quality
DeepSeek V4 Pro, released in April 2026 with an MIT open-source license, delivers competitive benchmark scores at a fraction of closed-model API costs. Kimi K2.6 from Moonshot AI reached top-10 on GPQA Diamond at $0.60 per million output tokens. GLM-5.1 from Zhipu AI topped SWE-bench Pro among open models. The moat that kept proprietary labs ahead on pure capability has narrowed significantly.
For US enterprise teams that need data sovereignty or custom fine-tuning, open-weight models are now a credible production option, not just a research exercise.
Enterprise adoption has crossed the tipping point
Gartner projects worldwide AI spending at $2.52 trillion in 2026, up 44% year over year. McKinsey’s State of AI 2025 survey found that 88% of organizations use AI in at least one business function. The average enterprise runs 4.2 AI models in production. Anthropic reached $30 billion in annualized revenue in April 2026, surpassing OpenAI’s $25 billion ARR. The market has moved from experimentation to infrastructure.
The five leading AI models in 2026
Claude Opus 4.7 (Anthropic)
Claude Opus 4.7, released April 16, 2026, is Anthropic’s current flagship. It holds the top position on SWE-bench Verified at 87.6% and SWE-bench Pro at 64.3%, both the highest published scores for real-world software engineering tasks. It also leads on GDPval, Anthropic’s knowledge-work benchmark that tests professional-grade deliverables across 44 occupations, with an Elo score of 1,753 versus GPT-5.5’s 1,674.
Claude Opus 4.7 supports a 1-million-token context window and 128,000-token output. Its hallucination rate on long-form factuality tests is significantly lower than GPT-5.5, making it the preferred choice for client-facing writing, compliance documentation, and any work where accuracy is the product. API pricing sits at $15 per million input tokens and $75 per million output tokens, making it the most expensive frontier option. The Claude Pro consumer plan costs $20 per month.
For a full head-to-head breakdown, see our Claude vs ChatGPT 2026 comparison and our Claude vs Gemini 2026 guide.
For a separate look at AI-provider policy and government procurement, read our Pentagon AI deals report.
GPT-5.5 (OpenAI)
GPT-5.5, released April 23, 2026, is the first fully retrained OpenAI base model since GPT-4.5. Its architecture is natively omnimodal, processing text, images, audio, and video in a single unified system. It leads the Artificial Analysis Intelligence Index at 60 and Terminal-Bench 2.0 at 82.7%, the best score on agentic terminal workflows published to date.
OpenAI reported 33% fewer false individual claims compared to GPT-5.2. For autonomous agents that need to call tools, maintain state across long tasks, and recover from errors, GPT-5.5 has become the first OpenAI model to lead over Anthropic on agentic execution benchmarks since GPT-4. API pricing is $5 per million input tokens and $30 per million output tokens. ChatGPT Plus costs $20 per month.
See our Gemini vs GPT-5 comparison for the full benchmark breakdown between these two models.
Gemini 3.1 Pro (Google DeepMind)
Gemini 3.1 Pro, released February 19, 2026, leads every published reasoning benchmark as of May 2026: GPQA Diamond at 94.3% for graduate-level scientific reasoning and ARC-AGI-2 at 77.1% for novel, memorization-proof abstract reasoning. It is also the only top-tier model with native audio and video input at the API level, giving it a structural advantage for multimodal enterprise workloads.
At $2 per million input tokens and $12 per million output tokens, Gemini 3.1 Pro is roughly one-quarter the cost of Claude Opus 4.7 at the same context tier. Its 1-million-token context window and 120+ tokens-per-second output speed make it the most cost-efficient frontier model for high-volume production workloads. Google AI Pro costs $20 per month for consumers.
Grok 4.3 (xAI)
Grok 4.3, released April 30, 2026, is xAI’s current flagship. Its key differentiator is real-time integration with X (formerly Twitter) data, a capability no other model matches at this depth. On Humanity’s Last Exam, which tests cutting-edge scientific knowledge at the absolute frontier, Grok leads at 50.7%. API pricing is $1.25 per million input tokens and $2.50 per million output tokens, making it competitive on cost with mid-tier models despite frontier capability. The SuperGrok consumer plan costs $30 per month.
For teams that need live social data, financial signals, or real-time market intelligence integrated into AI workflows, Grok 4.3 is the only serious option. See our full Grok vs ChatGPT vs Claude 2026 breakdown for the complete comparison.
DeepSeek V4 Pro (DeepSeek)
DeepSeek V4 Pro, released April 24, 2026 with an MIT open-source license, is a 1.6-trillion-parameter mixture-of-experts model with 49 billion activated parameters and a 1-million-token context window. It scores 52 on the Artificial Analysis Intelligence Index, placing it well above average among open-weight models. Standard API pricing is $1.74 per million input tokens and $3.48 per million output tokens, with a 75% promotional discount through May 31, 2026. Because it is open-weight, teams can self-host entirely for zero API cost given sufficient GPU infrastructure.
Benchmark comparison: who wins what
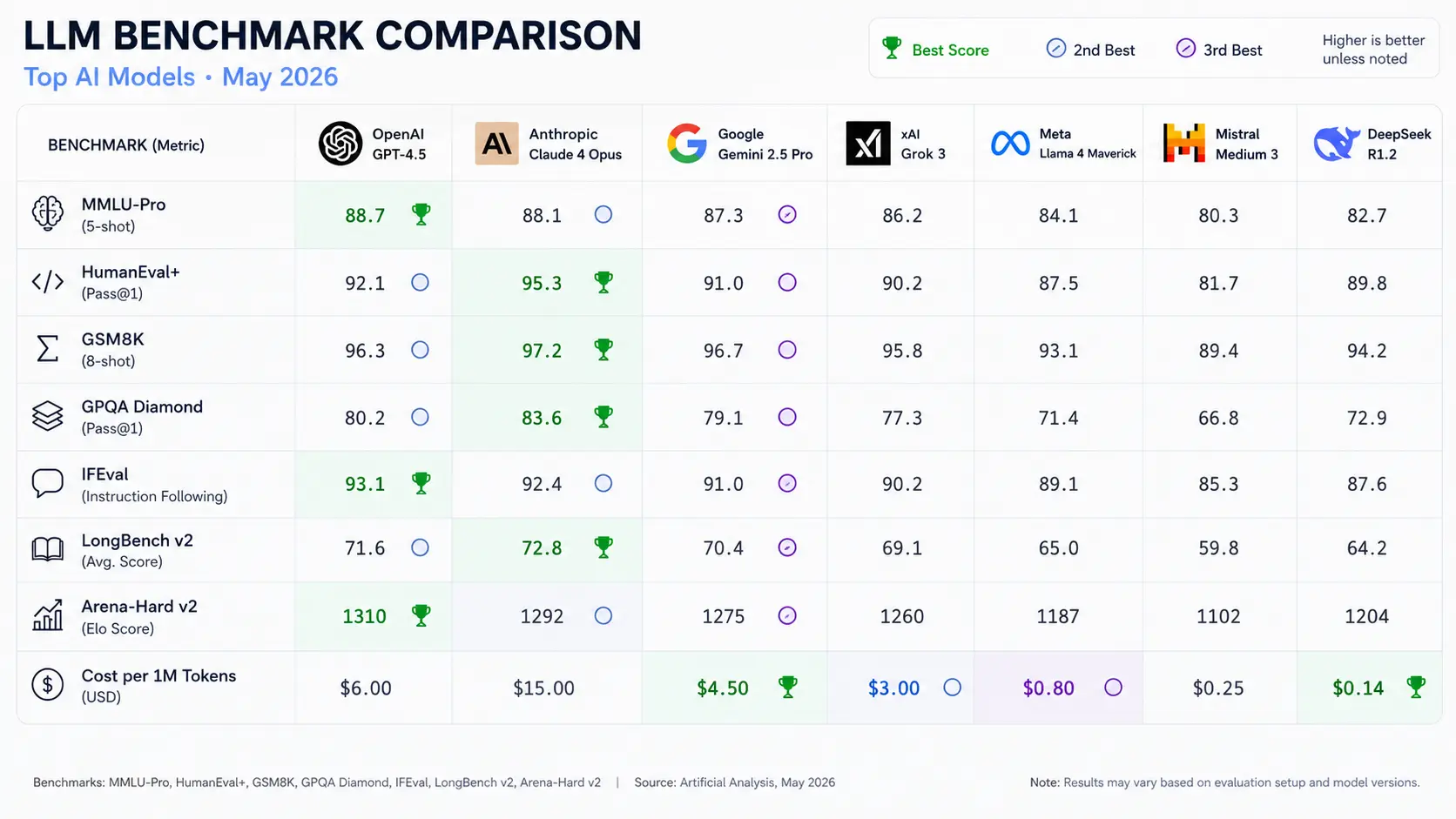
These are the benchmarks that reflect real production capability in 2026, not legacy tests that have been saturated by training data. All scores are third-party verified unless noted.
| Benchmark | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro | Grok 4.3 | Winner |
|---|---|---|---|---|---|
| SWE-bench Verified coding | 87.6% | 88.7% | 80.6% | 75% | GPT-5.5 (narrow) |
| SWE-bench Pro hard coding | 64.3% | 58.6% | 54.2% | N/A | Claude Opus 4.7 |
| GPQA Diamond reasoning | ~91% | ~92% | 94.3% | N/A | Gemini 3.1 Pro |
| ARC-AGI-2 abstract reasoning | N/A | N/A | 77.1% | N/A | Gemini 3.1 Pro |
| Terminal-Bench 2.0 agents | 69.4% | 82.7% | 68.5% | N/A | GPT-5.5 |
| Humanity’s Last Exam | N/A | N/A | N/A | 50.7% | Grok 4.3 |
| AI Intelligence Index overall | 57 est. | 60 | 57 | N/A | GPT-5.5 |
| Writing quality blind eval | 47% preferred | 29% preferred | 24% preferred | N/A | Claude Opus 4.7 |
Third-party verified scores. N/A = no published result at time of writing. Sources: SWE-bench leaderboard, Artificial Analysis Intelligence Index, April–May 2026.
The headline finding from this table: no single model dominates every benchmark. Claude Opus 4.7 is unambiguously the best for complex, hard coding tasks where getting it right matters more than speed. GPT-5.5 is the best for autonomous agentic workflows. Gemini 3.1 Pro leads every published reasoning benchmark. Grok 4.3 leads at the frontier of scientific knowledge. Writing quality, measured by human blind preference evaluations, goes to Claude by a significant margin.
Pricing: what you actually pay in 2026
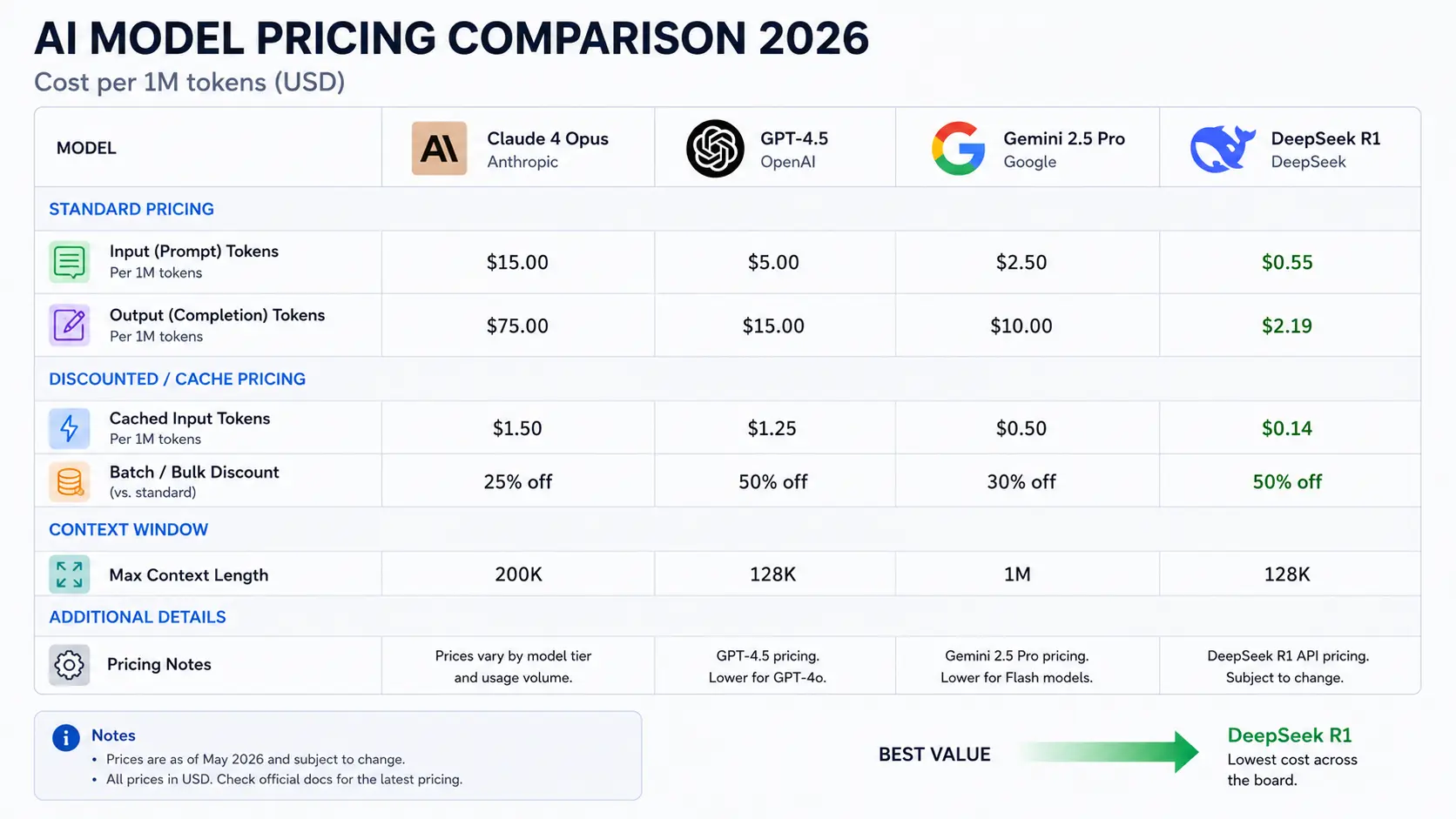
Consumer subscription pricing
The consumer tier has converged in 2026. Claude Pro, ChatGPT Plus, and Google AI Pro all sit at $20 per month. This price floor reflects years of testing: $20 is the ceiling at which typical users engage before churning. The convergence is starting to fracture at the premium end, where xAI’s SuperGrok Heavy reaches $300 per month for power users who need maximum Grok throughput.
Consumer plans · May 2026
Subscription pricing: free, standard, and premium
| Platform | Free tier | Standard ($20/mo) | Premium |
|---|---|---|---|
| ClaudeAnthropic | Claude Sonnet 4.6, limited | Claude Pro: full Opus 4.7 access | $100/moClaude Max |
| ChatGPTOpenAI | GPT-5.5, limited | ChatGPT Plus: full GPT-5.5 | $200/moChatGPT Pro |
| GeminiGoogle | Gemini Flash, limited | Google AI Pro: Gemini 3.1 Pro | $249.99/moGoogle AI Ultra |
| GrokxAI | Grok 4.3 via X, limited | SuperGrok: $30/mo | $300/moSuperGrok Heavy |
| Perplexity | Limited searches | Perplexity Pro: $20/mo | $200/moPerplexity Max |
Consumer pricing as of May 2026. All prices in USD. Claude Pro, ChatGPT Plus, and Google AI Pro all converge at the $20/mo standard tier.
For a detailed breakdown of whether the $20 upgrade is worth it on the two dominant platforms, see our Claude vs ChatGPT 2026 comparison.
API pricing for developers and enterprises
The API pricing gap in 2026 is dramatic. GPT-5.5 and Claude Opus 4.7 represent the premium tier. Gemini 3.1 Pro sits in the mid-tier. DeepSeek V4 Flash has reset expectations for what budget-tier performance looks like.
API pricing · May 2026
Developer and enterprise API rates
| Model | Input per 1M tokens | Output per 1M tokens | Context window |
|---|---|---|---|
| Claude Opus 4.7 | $15.00 | $75.00 | 1M tokens |
| GPT-5.5 | $5.00 | $30.00 | 256K tokens |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 200K tokens |
| GPT-5.4 | $2.50 | $15.00 est. | 1M tokens |
| Gemini 3.1 Pro | $2.00 | $12.00 | 1M tokens |
| Grok 4.3 | $1.25 | $2.50 | 1M tokens |
| DeepSeek V4 Pro | $1.74 promo $0.44 until May 31 | $3.48 promo $0.87 until May 31 | 1M tokens |
| DeepSeek V4 Flash | $0.14 | $0.28 | 1M tokens |
API pricing from official provider pages and OpenRouter, May 2026. DeepSeek V4 Pro promo ends May 31, 2026. All prices in USD.
The gap between premium and budget is striking: on output tokens, GPT-5.5 at $30 per million versus DeepSeek V4 Flash at $0.28 per million is a 107x difference. For teams building production systems at scale, this pricing gap changes the math entirely, especially for workloads where the cheaper model performs within a few percentage points on the benchmarks that matter for that task.
Decision matrix: which model to use for your task
Use this as a starting point, then test on your actual workload. Benchmark scores and real-world performance on your specific prompts can diverge.
| Task | Best model | Budget alternative | Why |
|---|---|---|---|
| Complex coding and code review | Claude Opus 4.7 | Gemini 3.1 Pro | Leads SWE-bench Pro by 5.7 points; strongest on hard multi-file changes |
| Autonomous agents and computer use | GPT-5.5 | Claude Opus 4.7 | Terminal-Bench 82.7% is best published score; first OpenAI lead over Anthropic on agentic execution |
| Scientific reasoning and research | Gemini 3.1 Pro | Claude Opus 4.7 | Leads GPQA Diamond at 94.3% and ARC-AGI-2 at 77.1% |
| Long-form professional writing | Claude Opus 4.7 | Claude Sonnet 4.6 | 47% preferred in blind evaluations vs 29% for GPT-5.5; lowest hallucination rate on long outputs |
| Multimodal tasks (image, video, audio) | Gemini 3.1 Pro | GPT-5.5 | Only frontier model with native audio and video input at the API level |
| Real-time data and social intelligence | Grok 4.3 | Perplexity Pro | Deep X/Twitter integration; no other model matches real-time social data access |
| High-volume batch processing | DeepSeek V4 Flash | Gemini 3.1 Flash-Lite | $0.14/$0.28 per million tokens; 79% SWE-bench Verified; open weights for self-hosting |
| General everyday productivity | GPT-5.5 | Claude Sonnet 4.6 | Broadest ecosystem, largest plugin library, most mature enterprise integration stack |
Recommendations based on benchmark data and independent testing as of May 2026.
For a detailed breakdown of how ChatGPT compares to its competitors across everyday tasks, see our guide on ChatGPT alternatives in 2026.
Choosing by user type
Developers and software engineers
Start with Claude Opus 4.7 for complex reasoning-heavy code work. Use Claude Sonnet 4.6 at $3/$15 per million tokens for everyday coding tasks where Opus quality is not required. Route terminal-heavy workflows and agentic pipelines to GPT-5.5. For any workload that can tolerate a 5-10% quality delta, Gemini 3.1 Pro at $2/$12 per million tokens delivers strong SWE-bench scores at significantly lower cost.
Content writers and marketers
Claude Opus 4.7 or Sonnet 4.6 for drafting: the tone consistency advantage across long documents is real and measurable in blind evaluations. GPT-5.5 Canvas for editing and restructuring: the integrated document editor is the best in the market. For SEO research and fact-heavy content, Gemini 3.1 Pro’s deep research mode with Google Search grounding is the most factually accurate option.
Business and enterprise decision-makers
The average enterprise in 2026 runs 4.2 AI models in production. Do not build a strategy around a single vendor. Start with a multi-model API layer. Use Gemini 3.1 Pro for bulk processing and research. Use Claude Sonnet 4.6 for day-to-day work. Reserve Claude Opus 4.7 or GPT-5.5 for the most demanding tasks. This routing approach typically cuts monthly API spend by 50-65% compared to running everything through a single flagship model.
Multi-model routing: how serious teams use AI in 2026
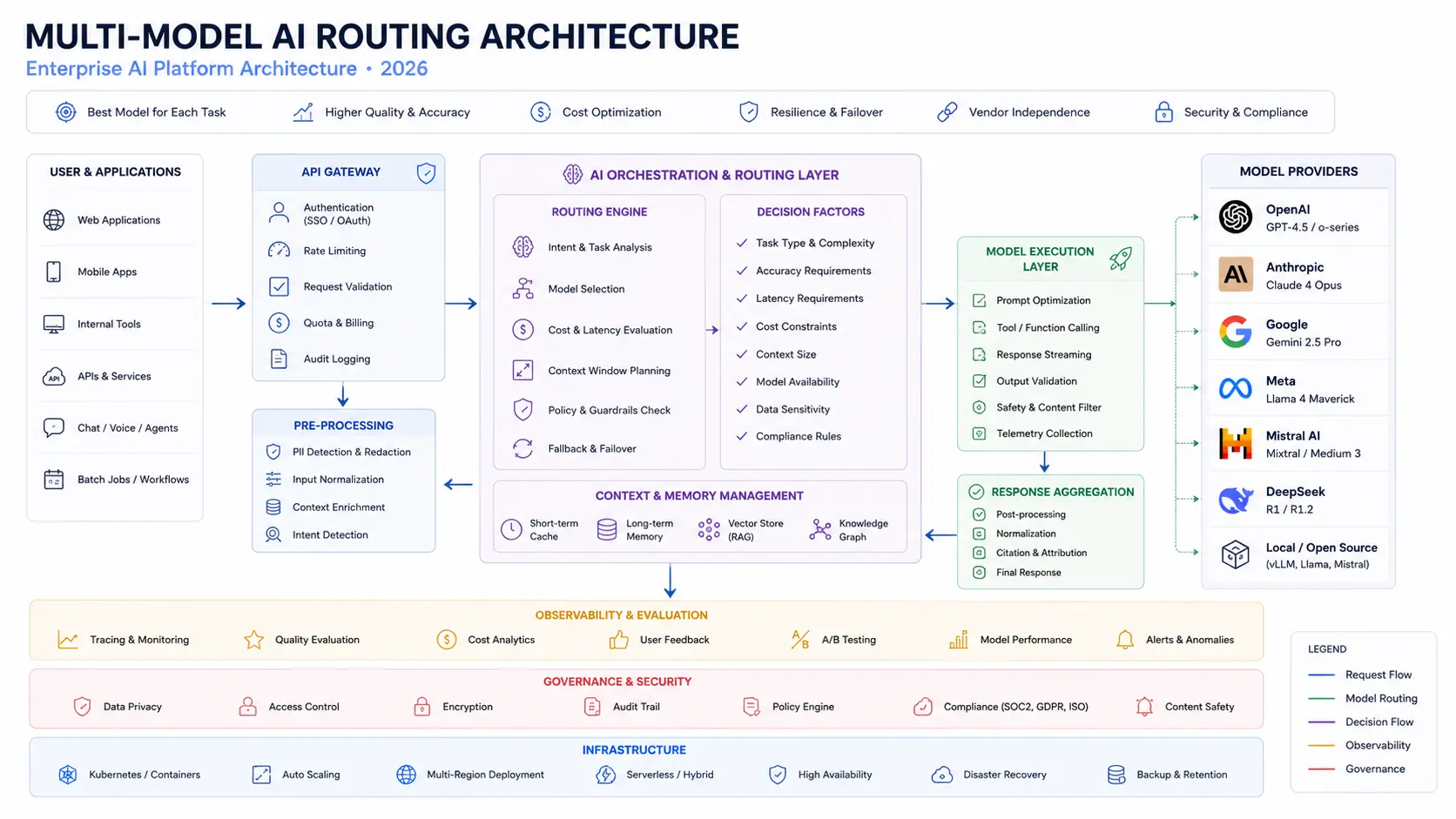
The most important strategic shift in 2026 is not which model to use. It is the architecture decision to stop treating model selection as a loyalty choice and start treating it as a routing problem.
The typical production routing setup used by cost-conscious engineering teams in May 2026 works like this:
- 70% of traffic to a budget model: DeepSeek V4 Flash ($0.14/$0.28 per million tokens) handles classification, summarization, simple extraction, and repetitive tool calls. Routing this volume away from frontier models eliminates most of the cost.
- 25% to a mid-tier model: Claude Sonnet 4.6 ($3/$15 per million tokens) handles everyday developer tasks, email drafting, moderate-complexity coding, and standard agent steps where quality matters but flagship capacity is not needed.
- 5% to a frontier flagship: Claude Opus 4.7 or GPT-5.5 handles the hardest tasks: complex multi-file code refactors, agentic reasoning chains, compliance-critical documents, and long-form analysis where error costs are high.
Teams using this architecture report overall performance indistinguishable from all-frontier routing at approximately 15% of the cost. With LLM Stats tracking over 250 model releases in Q1 2026, any team hardcoded to a single provider is also accumulating technical debt. The routing layer, not the model choice, is where the most significant productivity and cost gains remain in 2026.
Platforms like OpenRouter and EvoLink allow A/B testing across providers through a single OpenAI-compatible API endpoint, which removes the engineering friction from switching models as the leaderboard shifts.
What to watch out for: limitations and hallucination risks
Hallucination rates have not improved as fast as benchmark scores
Every reasoning model tested in May 2026 exceeds a 10% hallucination rate on Vectara’s long-form factuality dataset. GPT-5.5’s hallucination rate on long-form tasks sits at approximately 86%, versus Claude Opus 4.7’s 36% on the same evaluation. That gap is substantial for any client-facing writing, research summary, or compliance work where an error carries real cost. The takeaway: for agentic tasks where the model grounds itself in tool outputs, GPT-5.5’s hallucination disadvantage shrinks. For pure long-form writing, Claude’s accuracy advantage is real and meaningful.
Benchmark gaming is real and getting harder to detect
Labs now optimize models against the benchmarks that matter for their marketing narrative. Independent evaluators like Artificial Analysis, LLM Stats, and BenchLM run standardized test harnesses that avoid the worst contamination, but even those can be influenced by training choices. The safest policy: treat vendor-reported benchmark numbers with skepticism, cross-reference with third-party evaluations, and always run your own eval on your specific workload before making a major infrastructure commitment.
Context window does not equal context quality
Claude Opus 4.7 and Gemini 3.1 Pro both support 1-million-token context windows. GPT-5.5’s context window is 256K. But context window size and model performance inside long contexts are not the same thing. Most models degrade significantly in the middle of very long documents. Always test your specific document length and query type before assuming a 1M context window means 1M tokens of reliable recall.
Open-weight models introduce infrastructure overhead
DeepSeek V4 Pro is open-weight and can be self-hosted, which eliminates API costs. But hosting a 1.6-trillion-parameter model requires serious GPU infrastructure. For most US enterprises, the managed API at $1.74 per million input tokens is the practical option, with self-hosting reserved for teams that have dedicated ML infrastructure and a compelling reason for data sovereignty.
Frequently asked questions
What is the best AI model in 2026?
There is no single best AI model in 2026. Claude Opus 4.7 leads on coding with 87.6% SWE-bench Verified. Gemini 3.1 Pro leads on reasoning with 94.3% GPQA Diamond. GPT-5.5 leads on agentic workflows with 82.7% Terminal-Bench. The right model depends entirely on your primary use case and budget.
How much do the top AI models cost in 2026?
Consumer subscriptions for Claude Pro, ChatGPT Plus, and Google AI Pro all sit at $20 per month. API pricing varies widely: GPT-5.5 costs $5 per million input tokens and $30 per million output tokens. Gemini 3.1 Pro costs $2 input and $12 output per million tokens. DeepSeek V4 Flash is the cheapest production-grade option at $0.14 input and $0.28 output per million tokens.
Which AI model is best for coding in 2026?
Claude Opus 4.7 is the best AI model for coding in 2026. It leads SWE-bench Pro at 64.3% and SWE-bench Verified at 87.6%, both the highest scores published as of May 2026. For budget-conscious teams, Gemini 3.1 Pro delivers 80.6% SWE-bench Verified at less than half the cost per API token.
Is GPT-5.5 better than Claude Opus 4.7?
GPT-5.5 and Claude Opus 4.7 lead in different categories. GPT-5.5 leads the Artificial Analysis Intelligence Index at 60 and Terminal-Bench at 82.7% for agentic workflows. Claude Opus 4.7 leads SWE-bench Pro at 64.3% for complex coding and produces more reliable long-form writing with significantly lower hallucination rates. Neither is universally better.
What is the cheapest AI model that still performs well in 2026?
Gemini 3.1 Pro offers the strongest price-to-performance ratio among closed frontier models at $2 per million input tokens. Among open-weight models, DeepSeek V4 Flash at $0.14 per million input tokens delivers 79.0% SWE-bench Verified, which is competitive with flagship models from six months ago. Kimi K2.6 from Moonshot AI also reaches frontier-quality reasoning at $0.60 per million output tokens.
Should I use multiple AI models or stick to one?
Most serious teams in 2026 use multi-model routing rather than committing to a single provider. A typical production setup routes the majority of traffic to a cost-efficient model like DeepSeek V4 Flash or Gemini 3.1 Flash, a smaller portion to a mid-tier model like Claude Sonnet 4.6, and the smallest share to a frontier model for complex tasks. This approach achieves near-frontier performance at roughly 15% of the all-frontier cost.
Go deeper: the complete LLM comparisons series
This article is the hub of the LLM Comparisons cluster on BriefArticle. Use the related guides below when you need a deeper head-to-head comparison or a tool-specific recommendation:
- Claude vs ChatGPT 2026: Full Comparison (Tested) – head-to-head across writing, coding, reasoning, and pricing.
- Gemini vs GPT-5 2026: Benchmarks, Pricing, Best Use Cases – the best follow-up if you are choosing between Google and OpenAI.
- Perplexity vs ChatGPT 2026: Which AI Search Engine Wins – search quality, citations, real-time answers, and pricing.
- ChatGPT Alternatives 2026: 7 AI Tools That Beat It at Specific Tasks – practical alternatives when ChatGPT is not the best fit.
- GPT-5.5 Instant: hallucinations, default model changes, and what users should know – deeper context on OpenAI’s current default model.
- AI Tools 2026: The Complete Guide to Every Category – the broader AI tools hub for business use cases.
- Best AI Tools for Small Business 2026 – the commercial stack for founders, teams, and operators.
Bottom line
The best AI model in 2026 is the one that matches your specific task: Claude Opus 4.7 for coding and writing quality, Gemini 3.1 Pro for reasoning and cost-sensitive workloads, GPT-5.5 for autonomous agents and the broadest ecosystem. No single model dominates everything, and the leaderboard reshuffles every few weeks as new releases land.
The more important decision in 2026 is architecture, not allegiance. Teams that build multi-model routing from the start will outperform teams that bet everything on a single vendor, both on performance and on cost. The infrastructure gap between those two approaches is compounding quickly as new and cheaper models keep arriving.
To go deeper on any specific pair, start with our Claude vs ChatGPT 2026 comparison or the full ChatGPT alternatives guide for the most actionable breakdown on each use case.
Get the daily AI brief
Delivered at 7:30 AM EST, Monday to Friday. The signal without the noise. Free. No fluff. Unsubscribe anytime.




